1.引言 在 DeepSeek 上,我们几乎可以查询所有问题,但仍有一些问题无法回答。例如,在医院场景中,提问的问题可能涉及专业的医疗知识,需要根据医院的病历诊断进行分析和回答。然而,这些资料通常不对外公开,DeepSeek 无法学习到这些知识。
要实现这一功能,有以下两种方法:
单独训练模型 :使用医院特有的资料进行训练。但这种方法复杂且成本高,及时性也难以保证。
结合现有大模型和外部资料 :让大模型根据外部资料生成答案。这种方法成本较低,且资料更新后可以及时反映在回答中。
第二种方法正是我们今天要探讨的 RAG(Retrieval-Augmented Generation)技术 。
2.什么是 RAG RAG(检索增强生成)技术 是一种结合 信息检索(Retrieval) 和 文本生成(Generation) 的 AI 解决方案。它在 传统生成式 AI(如 DeepSeek) 的基础上引入外部知识库,从而提高回答的准确性、时效性和可靠性。
RAG 系统的核心思想
传统的 LLM(大语言模型)只能依靠 训练时存储的知识 进行回答,而 RAG 允许模型在生成答案时 动态查询外部知识库 。
这样可以一定程度避免 LLM 幻觉问题(hallucination) ,提升事实准确性,并降低对大规模参数模型的依赖。
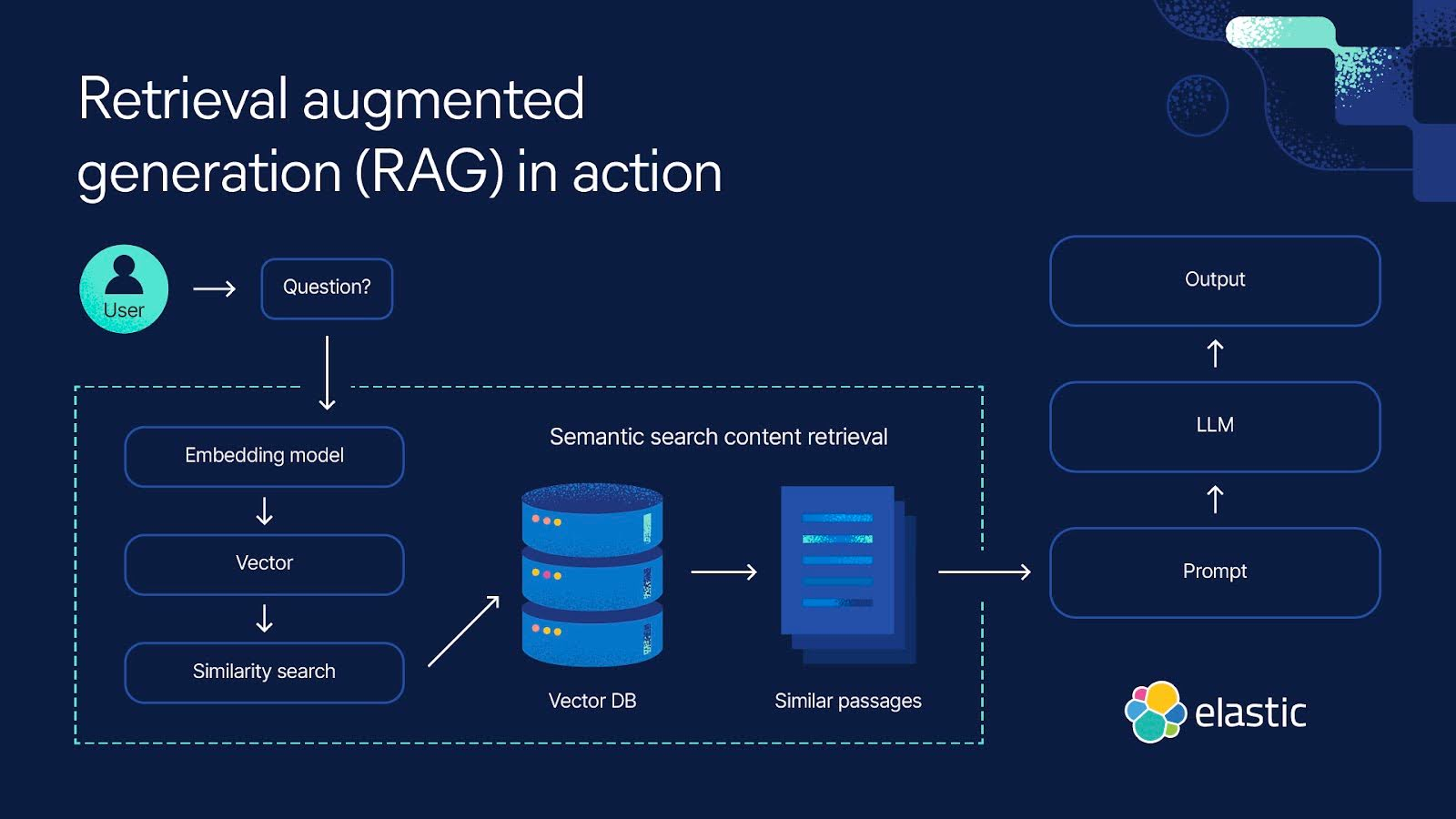
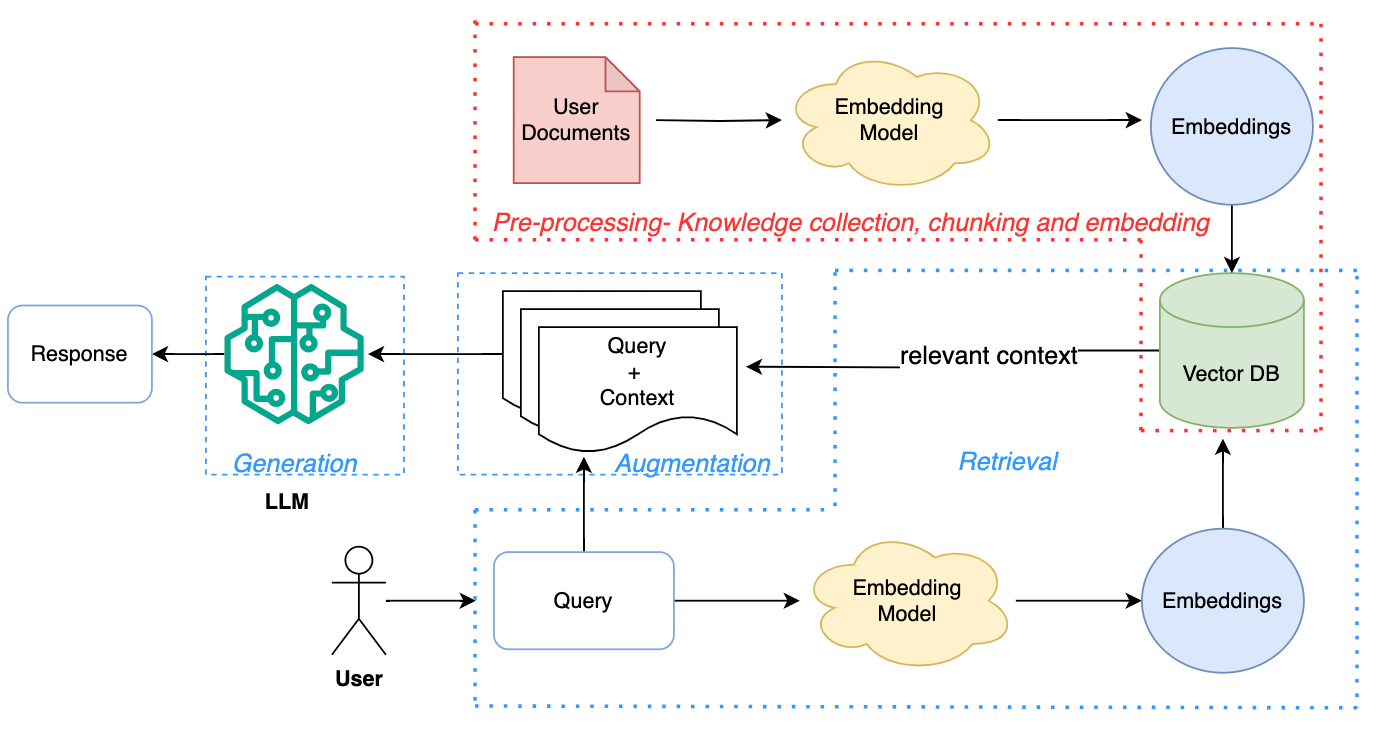
找到的两张关于 RAG 架构的流程图:
RAG 系统的基本组成 从上图中我们可以看出一个 RAG 系统大致有以下几个部分:
1. 资料处理功能 将现有的文档资料进行向量化处理,并存入向量数据库中,供后续查询使用。这一过程需要借助文本转向量的工具或模型。
2. 资料检索功能 负责从向量数据库中检索与输入问题相关的文档或段落。检索流程如下:
把用户输入的问题转变成向量(需要借助 文本转变向量 的工具或模型)。
根据问题向量,在 向量数据库 中进行相似度计算,得到一批相关文档。
3. 文本生成功能 利用检索到的相关资料,调用 LLM(生成式大模型)生成最终答案。技术方案是通过构造 Prompt(提示词),将检索结果拼接到查询中,使大模型能够精确回答。
3.RAG 系统实现 接下来,我们将从零开始实现一个简单的 RAG 系统。
先做一些准备工作:
使用 conda 新建一个环境 rag-demo,后续的所有命令都在这个环境中执行。
1 2 conda create -n rag-demo python=3 .10 conda activate rag
确保有部署好的 DeepSeek 服务,或使用在线的 DeepSeek 服务。如需自行部署 DeepSeek,可参考上一篇文章:基于 vLLM 的 DeepSeek 模型部署与接口调用实践 。
资料处理功能实现 这个部分有两个重要的组件:文本转向量的工具和向量数据库。
文本转向量工具选择 文本转向量是整个系统的基础。如果向量构建不准确,后续查询将失去意义。
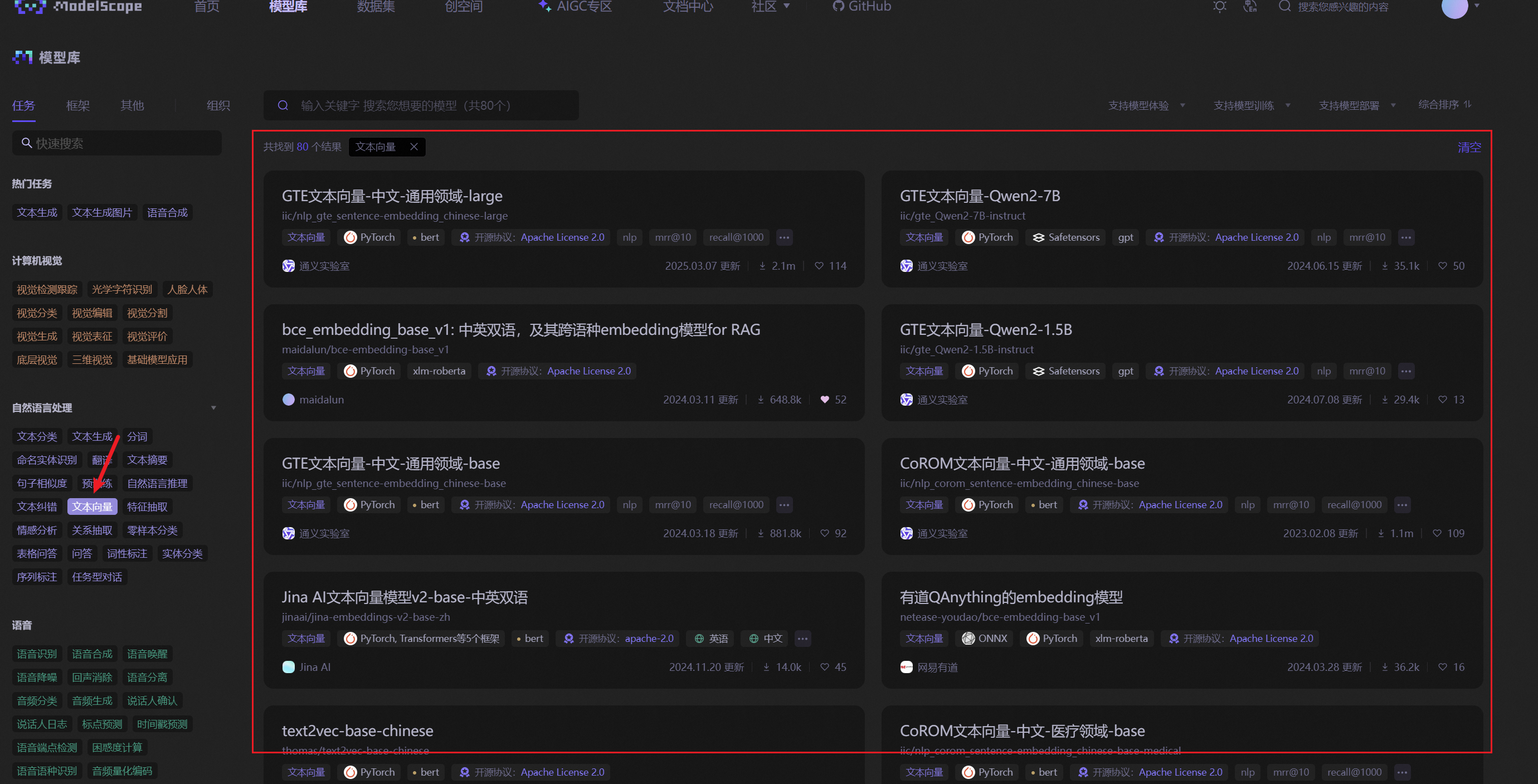
这里我们进入魔塔社区:https://modelscope.cn/models,在左边标签自然语言处理模块选择"文本向量"标签,就可以看到一些文本转向量的模型。
如果使用这里的模型,对机器也是有一定的要。我选择了文本向量模型:nlp_gte_sentence-embedding_chinese-small )。
使用modelscope 下载模型
1 2 3 4 5 6 7 from modelscope import snapshot_download "iic/nlp_gte_sentence-embedding_chinese-small" ,cache_dir="D://ai/model" )
模型的使用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from modelscope.models import Modelfrom modelscope.pipelines import pipelinefrom modelscope.utils.constant import Tasks"D:/ai/model/iic/nlp_gte_sentence-embedding_chinese-small" 512 "source_sentence" : ["不可以,早晨喝牛奶不科学" ,"吃了海鲜后是不能再喝牛奶的,因为牛奶中含得有维生素C,如果海鲜喝牛奶一起服用会对人体造成一定的伤害" input =inputs)print (result)
输出结果如下,默认向量维度512 .
1 2 [[-0 .0457 -0 .0622 -0 .0378 ... 0.01267 -0 .0111 -0 .03387 ]-0 .0207 -0 .0464 -0 .0482 ... -0 .007526 -0 .00732 -0 .02739 ]]
我们看上面的代码,还会发现一个问题,文本转向量的接口一次接受的文本长度是有限制的,比如上面我们设置了 512(单位没确认,姑且认为是512字节吧)。资料文档一个文件可能是很大的,这个时候需要需要对文件进行切割,然后一块块的进行向量化处理。这个对文档进行切割也是一门学问,大家可以自行查找资料。
我这里就默认使用 RecursiveCharacterTextSplitter 来进行处理,完整的文件切割处理代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 """ 文件读取和切分chunk fileName: file_util.py """ from loguru import logger import os from typing import List from langchain_core.documents import Document from langchain_text_splitters import RecursiveCharacterTextSplitter from llama_index.core import SimpleDirectoryReader from config.config import CHUNK_SIZE, CHUNK_OVERLAP def load_filedir_and_split_document (file_directory: str ) -> List [Document]: '.txt' ]).load_data() len , for doc in documents] for doc in documents] return text_splitter.create_documents(texts, metadatas)
文本向量处理代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 """ 描述: 文件向量化的接口 fileName: file_embedding_service.py """ from abc import ABCfrom typing import List , Any from loguru import loggerfrom modelscope.pipelines import pipelinefrom modelscope.utils.constant import Tasksfrom config.config import EMBEDDING_MODEL_PATH, CHUNK_SIZEclass FileEmbedding :def __init__ (self ):self .client = pipeline(10 def get_embeddings (self, texts: List [str ] ) -> List [List [float ]]:""" 获取文本的向量 :param texts: 文本列表 :return: 向量列表 """ input = {"source_sentence" : texts"start embedding input:" , input )self .client(input =input ).get("text_embedding" )"end embedding input:" , input )return resdef get_embedding (self, text: str ) -> List [float ]:""" 获取单个文本的向量 :param text: 文本 :return: 向量 """ input = {"source_sentence" : [text]return self .client(input =input ).get("text_embedding" )[0 ]if __name__ == '__main__' :"不可以,早晨喝牛奶不科学" ,"吃了海鲜后是不能再喝牛奶的,因为牛奶中含得有维生素C,如果海鲜喝牛奶一起服用会对人体造成一定的伤害" ,print ("Embeddings:" , embeddings)
向量数据库 找到一张网上的截图,向量数据库有很多,这里大家按需选择吧,我这里使用了 Qdrant 数据库。
Qdrant 数据库的安装官方是使用 docker 的,安装命令如下(关于如何使用 docker 镜像地址下载,大家可以自己查找下):
1 2 3 4 5 "$(pwd) /qdrant_storage:/qdrant/storage:z" qdrant/qdrant
官方文档地址:Home - Qdrant
docker 容器启动后,可以访问数据库的控制面板地址:
http://127.0.0.1:6333/dashboard#/collections
这个是数据库的 collections 界面
console 界面可以执行命令,进行创建、查询等操作。
这里我们先建一个 collection,名称是:rag-native-demo,我们上面使用的 nlp_gte_sentence-embedding_chinese-small 模型的默认向量大小是512,所以这里我们创建 collection 的时候指定的 size 也要是512.
1 2 3 4 5 6 7 PUT collections/rag-native -demo"vectors" : {"size" : 512 ,"distance" : "Cosine"
资料预处理 我们现在有了文本向量工具和向量数据库,就可以实现资料处理的功能了。核心方法:get_vector_store_index_native ,我们只要调用一下 get_vector_store_index_native("rag-native-demo") 方法,就会触发资料的加载处理逻辑。
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 from typing import List from qdrant_client import QdrantClient from qdrant_client.http.models import Distance, VectorParams, PointStruct from config.config import QDRANT_HOST, QDRANT_PORT, VECTOR_SIZEfrom utils.file_util import load_filedir_and_split_documentdef get_vector_store_index_native (collection_name: str ):""" 获取向量数据库集合对象 :param collection_name: :return: """ if collection.points_count > 0 :print ("集合有数据,直接返回" )else :print ("集合没有数据,初始化插入数据..." )f"读取数据完成,共{len (documents)} 条数据" )print ("数据初始化完成" )return collectiondef file_to_vector (documents: List [Document], collection_name: str ):""" 文本转换成向量并存储(分批次插入) :param documents: 文档列表 :param collection_name: 向量数据库集合名称 :return: """ 10 for i in range (0 , len (documents), batch_size):for doc in docs]for doc in docs]id =str (uuid.uuid4()), vector=embedding, payload=payload)for embedding, payload in zip (batch_embeddings, payloads)f"开始存入 {len (points)} 条数据" )f"已存入 {len (points)} 条数据" )f"所有文本数据已存入向量数据库,共 {len (documents)} 条数据" )def build_payloads (texts, metadatas ): "page_content" : text, "metadata" : metadata, for text, metadata in zip (texts, metadatas) return payloads
资料检索和文本生成实现 记过上一步,我们服务的基本组件都已将具备了。下面我们来实现根据输入内容来检索资料和文本生成的功能。
主要步骤:
把输入参数 query 转成向量。
根据步骤1的向量从向量数据库查询相关数据。
根据查询向量数据库得到的数据和 query 构建 promot (核心步骤) 根据构建的 promot 查询 deepseek 服务,得到响应结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 from loguru import logger from openai import OpenAI from config.config import DEEPSEEK_API_KEY, DEEPSEEK_BASE_URL, DEFAULT_MODEL class LLMDeepseekClient : def __init__ (self ): self .client = OpenAI(api_key=DEEPSEEK_API_KEY, base_url=DEEPSEEK_BASE_URL) self .model = DEFAULT_MODEL def get_completion_response (self, prompt ): """ 请求模型接口,获取响应结果 """ f"deepseek模型开始调用,当前模型:{self.model} " ) self .client.completions.create( self .model, 0.1 , 50 ,f"deepseek模型调用成功,当前模型响应结果:{response} " ) f"非流式输出 | total_tokens: {response.usage.total_tokens} " f"= prompt_tokens:{response.usage.prompt_tokens} " f"+ completion_tokens: {response.usage.completion_tokens} " ) return response.choices[0 ].textdef query_vector_store (collection_name: str , query: str , limit: int = 5 ): print (results) if not (results and results.points): return "没有查询到相关数据" "" for result in results.points: 'page_content' ] + "\n" f""" 你是一位 AI 助手,负责回答用户问题。请根据提供的检索内容,优化回答,使其更加完整、准确和可读。 **用户问题**: {query} **检索到的原始内容**: {relation_content} **优化后的回答**: """ print (f"构造的prompt==> {prompt} " ) return res
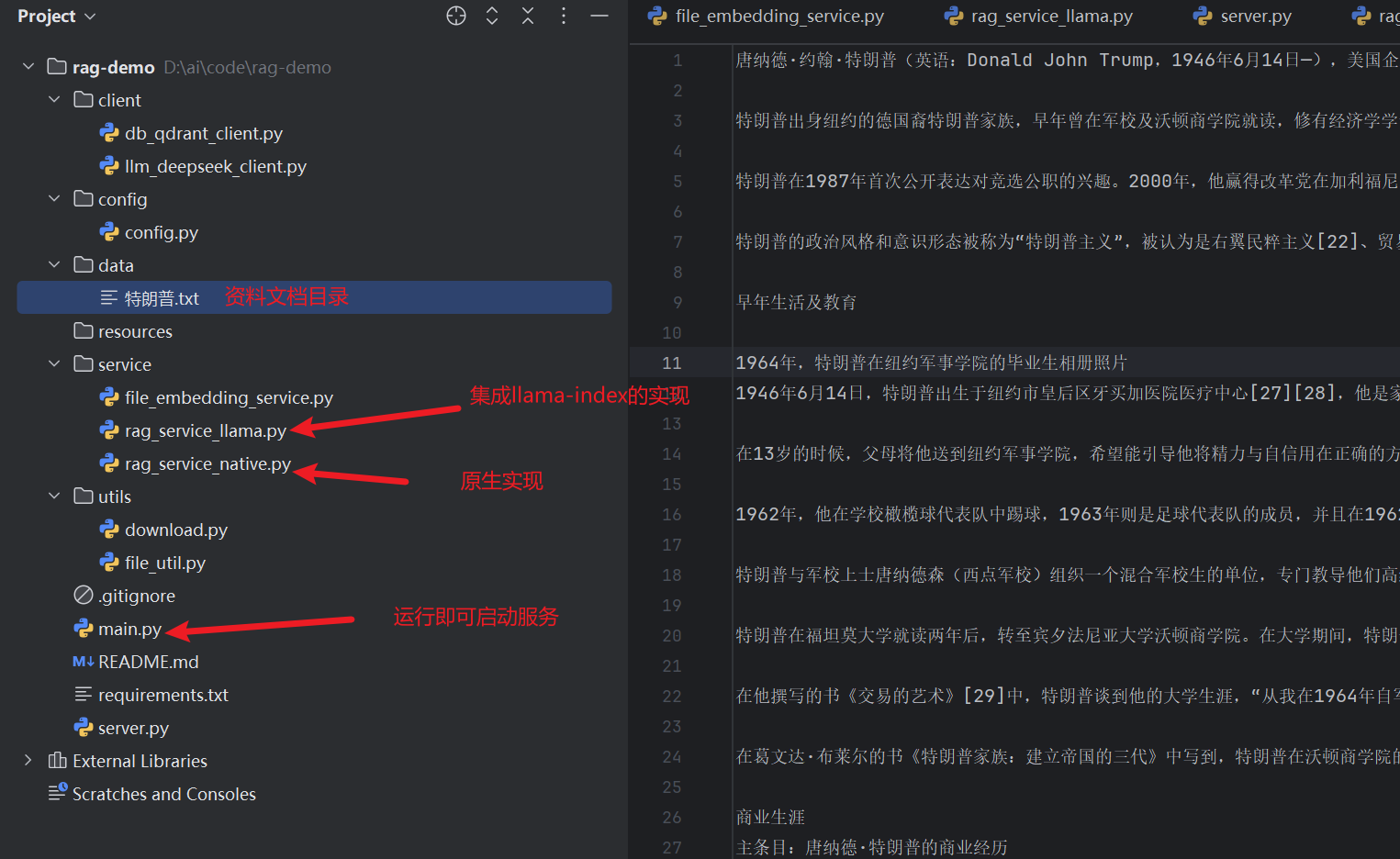
到这里,RAG系统的功能基本开发完毕了,因为项目代码比较多,都放文章里不太适合,完整的代码上传到了 github,其中还有集成 llama-index 的实现可供参考。
项目 git 地址:https://github.com/wydpp/rag-demo
项目的配置都在 config.py 文件中。
项目启动后,首先调用 http://127.0.0.1:8000/init 接口初始化资料。中间过程可能会有点慢,耐心等待。出现错误,可以重新在运行(向量数据库没数据,可以删掉 collection,重新在建一个然后再执行 init 接口 )。
然后可以分别调用下面两个接口来验证下效果:
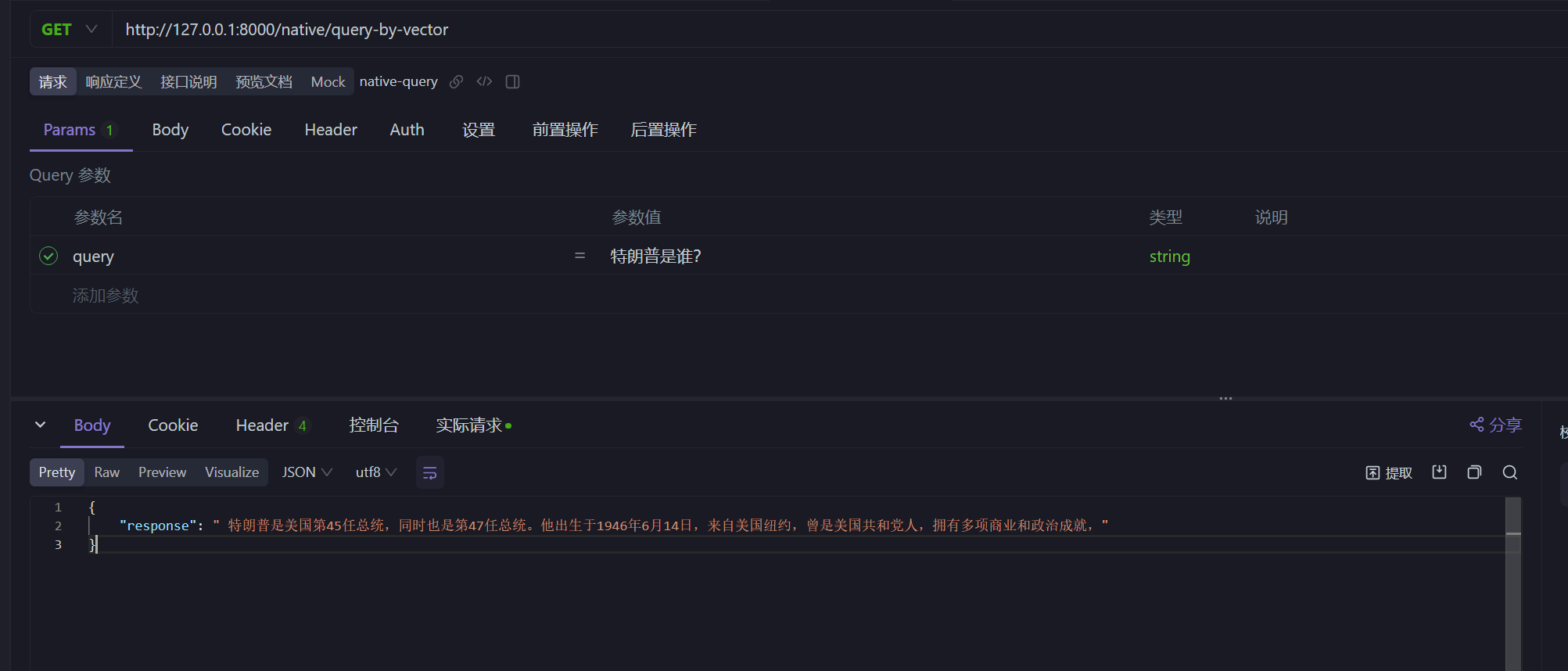
http://127.0.0.1:8000/native/query 直接查询 deepseekhttp://127.0.0.1:8000/native/query-by-vector 经过向量数据库的查询
项目中 data 的 txt 文件时关于特朗普的介绍,我们直接问 特朗普是谁? ,来看下两个接口的区别
直接查询 deepseek 的结果:
经过资料检索处理后的结果:
4. RAG 落地的挑战 在实际落地过程中,可能会遇到以下挑战:
文本资料的处理 :如何处理各种格式的资料、更新资料以及大文件的处理。文本检索的准确率 :如何提高根据问题检索相关资料的精确度。LLM 生成文本的随机性 :如何避免模型生成错误或无关的答案。大规模延迟问题 :如何在高并发场景下保证系统的高可用性和高性能。
其他我也不太清楚了,这是我想到的可能出现的一些问题。
5. 总结 本文介绍了基于 DeepSeek 大模型构建 RAG 系统的基础架构和实现。通过本文,您可以了解 RAG 系统的运行流程,为后续学习其他开源 RAG 工具或构建类似项目奠定基础。
完整代码已上传至 GitHub:rag-demo 。
本人水平有限,文中难免有错误之处,还请见谅。