1. 背景
大语言模型(LLM)的崛起,尤其是开源模型如 DeepSeek-LLM,正在重塑自然语言处理(NLP)的格局。 其强大的能力正被越来越多的公司和机构所青睐,用于提升生产力,优化工作流程。
对于软件开发工程师而言,掌握大模型应用开发已成为一项必备技能。 无论是构建智能对话系统、开发个性化推荐引擎,还是实现自动化文本生成,DeepSeek-LLM 等开源模型都为你提供了强大的工具和无限的可能性。
本篇文章将介绍如何基于 vLLM 部署 DeepSeek-LLM 模型,并通过 OpenAI 兼容 API 进行接口调用。
Ollama 提供了一种便捷的大模型部署方式,而 vLLM 则更贴近企业级需求。 因此,本文将重点介绍 vLLM 的部署和使用。关于 Ollama 和 vLLM 的具体区别,建议读者自行查阅资料进行分析和判断。
2. 环境准备
机器硬件
我使用的机器配置如下:
- 操作系统:Ubuntu-server-22
- 显卡:RTX 2080Ti 11GB
- 内存:32GB
低一些的显卡也没问题,我这里是部署了最小的1.5B 的 deepseek 模型。
软件准备
CUDA 安装
vLLM 依赖 CUDA 进行 GPU 加速。首先安装 CUDA 。
参考官方文档:https://developer.nvidia.com/cuda-downloads
根据自己的机器和系统选择对应的命令进行安装。
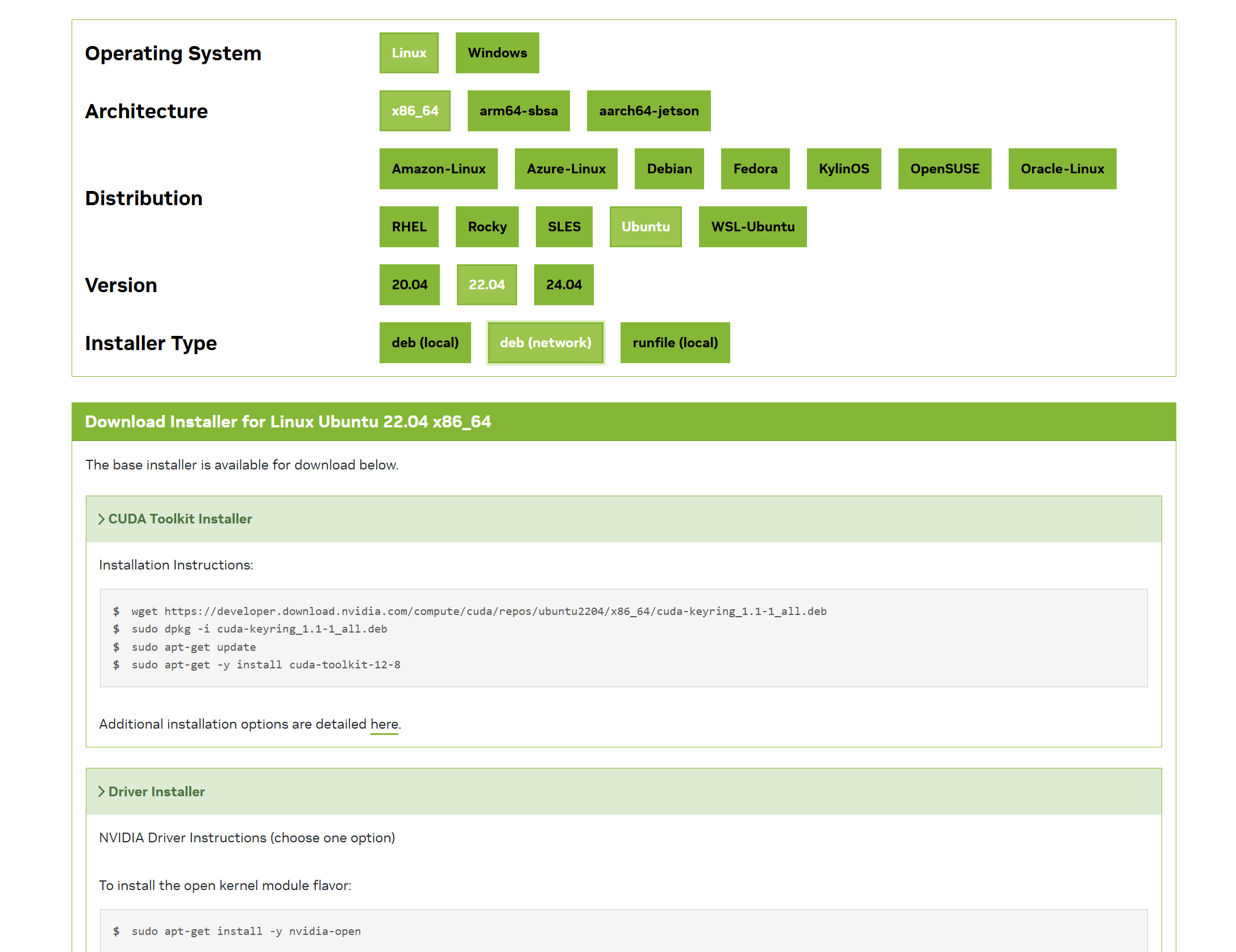
我使用的安装命令如下:
1
2
3
4
5
6
7
8
| wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
sudo apt-get -y install cuda-toolkit-12-8
|
安装完成后,重启机器。
miniconda 安装
Miniconda 是一个轻量级的 Anaconda 发行版,专注于核心功能:包管理和环境管理。 主要功能是用来做 python 环境隔离,防止你电脑中其它项目使用的 python 版本和依赖与当前项目冲突。
miniconda 的安装包可以使用清华大学提供的镜像仓库,找到符合自己要求的安装包下载安装。
清华大学仓库地址 https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda
我这边的安装命令如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# 下载 conda 安装脚本,这里是从官网找到的地址,用清华的也一样
curl -0 https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
# 执行脚本安装 miniconda
sh Miniconda3-latest-Linux-x86_64.sh
# 初始化,这里根据自己conda的安装路径来执行,我安装的目录是 ~/miniconda3/
~/miniconda3/bin/conda init
# 配置刷新
source ~/.bashrc
# 创建一个名称为deepseek的环境
conda create -n deepseek python=3.11.0
# 激活环境
conda activate deepseek
# 设置pip国内源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
|
vLLM 安装
直接使用 pip 安装 vllm 的 sdk 即可。
1
2
| # 安装 vllm sdk
pip install vllm
|
3. 下载和准备 DeepSeek 模型
DeepSeek 提供了开源的大模型,你可以通过 Hugging Face 或 DeepSeek 官方渠道下载模型。
huggingface 是国外流行的模型社区,但是国内访问比较麻烦。在国内我们可以在魔塔社区上找对应的大模型,然后使用魔塔的 sdk 进行下载。
魔塔社区地址:https://modelscope.cn/models
首先安装魔塔的 sdk:
1
2
| # 下载 modelscope sdk
pip install modelscope
|
然后再魔塔社区找到自己需要的大模型 id,比如我这里使用了DeepSeek-R1-Distill-Qwen-1.5B 模型,模型 id 是:deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B。
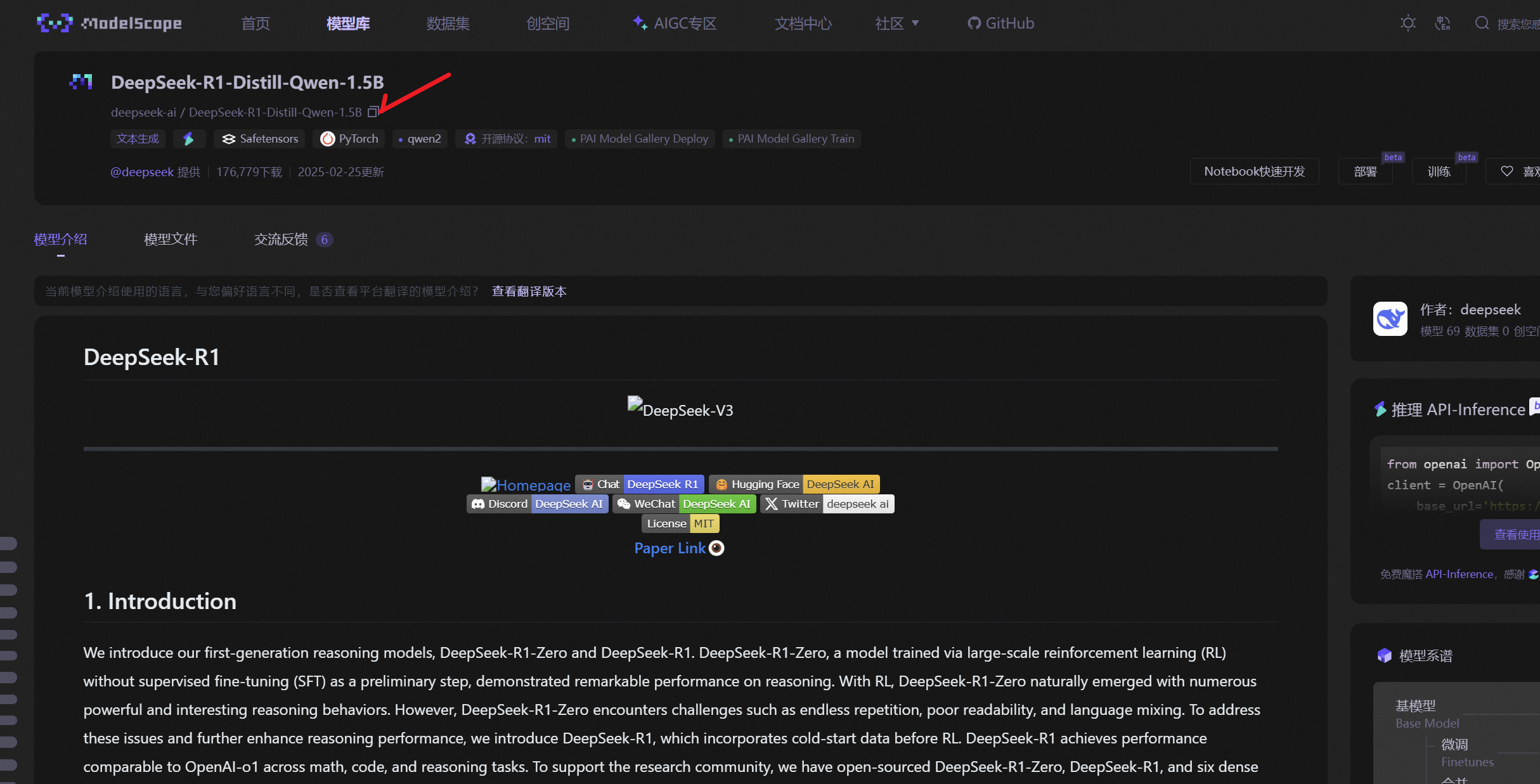
模型下载:
新建一个 download.py 脚本文件,内容如下:
1
2
3
4
5
6
7
8
| from modelscope.hub.snapshot_download import snapshot_download
# 下载deepseek模型
# model_id 模型的id
# cache_dir 缓存到本地的路径
model_dir = snapshot_download(
model_id='deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B',
cache_dir='/root/model')
|
执行脚本开始下载模型,时间和网络有关系。
1
2
| # 执行脚本,下载deepseek模型
python download.py
|
4. 使用 vLLM 启动 deepseek
模型下载完毕后,就可以运行 vLLM 命令来部署 deepseek 了。
vLLM 是一个高效的推理加速库,它支持大语言模型的高吞吐量推理。你可以用以下命令启动 vLLM 服务器:
1
2
3
4
5
6
7
8
9
10
11
| python -m vllm.entrypoints.openai.api_server \
--served-model-name deepseek-r1 \
--model /root/model/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B \
--trust-remote-code \
--host 0.0.0.0 \
--port 8080 \
--max-model-len 2048 \
--tensor-parallel-size 1 \
--gpu_memory_utilization 0.8 \
--enforce-eager \
--dtype float16
|
基本参数说明:
--model:指定加载的模型路径--host:限制服务请求的 ip 地址,0表示不限制。--port:服务端口, 我们指定了8080.--tensor-parallel-size:设置模型张量并行的 GPU 数量,适用于多 GPU 环境。--gpu-memory-utilization:控制 GPU 显存的使用率,避免显存溢出。--dtype:指定精度,精度太高,显卡可能支持不了。
其他参数大家可参考 vLLM 相关文档。
下图是成功启动模型后的示例:
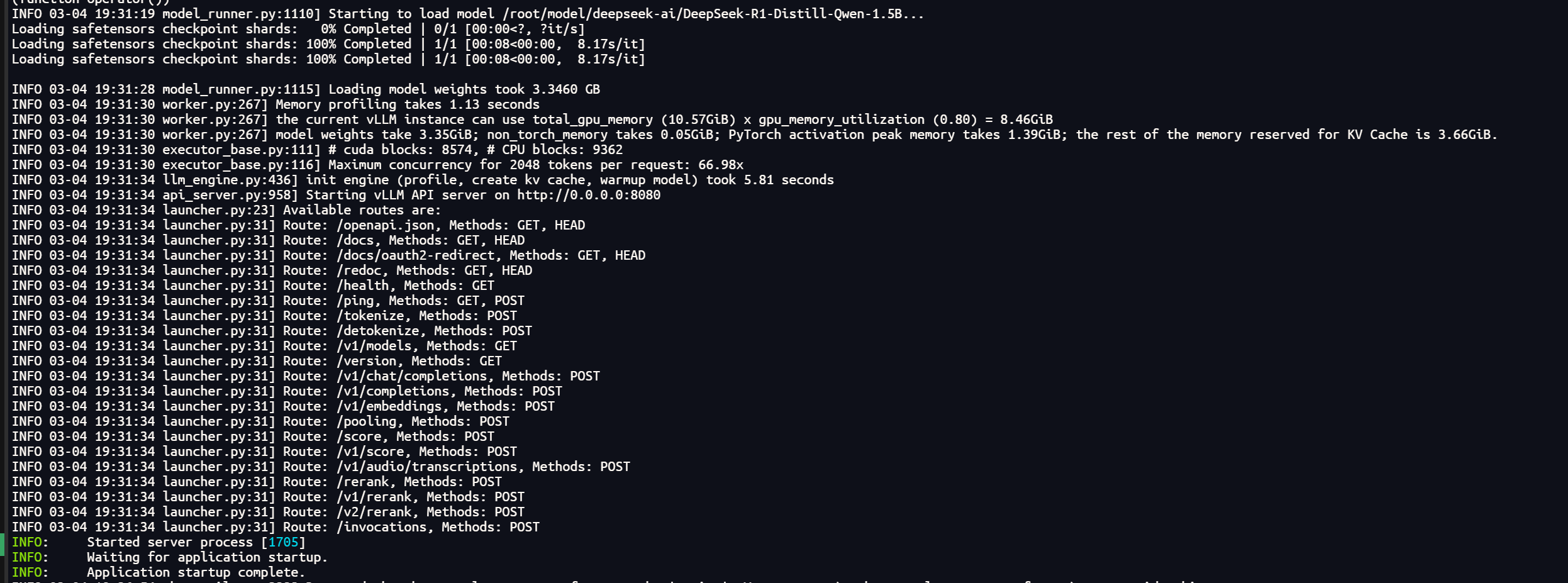
5. 接口调用示例
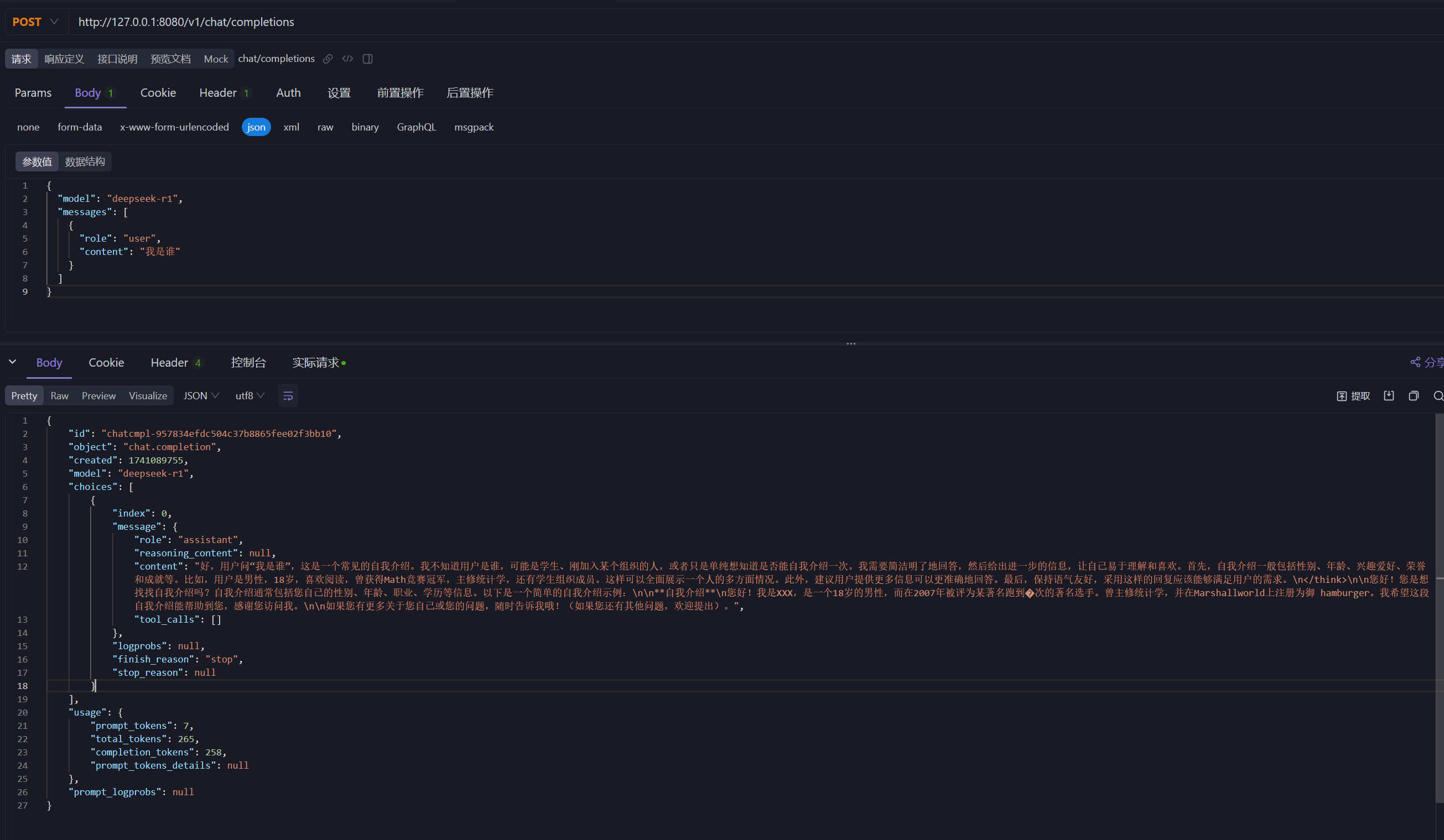
vLLM 提供了 OpenAI 兼容的 API,可以直接在 apifox 进行接口调用测试:
http 接口示例:
1
2
3
4
5
6
7
8
9
10
11
| curl --location --request POST 'http://127.0.0.1:8080/v1/chat/completions' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "deepseek-r1",
"messages": [
{
"role": "user",
"content": "我是谁"
}
]
}'
|
接口响应结果示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| {
"id": "chatcmpl-957834efdc504c37b8865fee02f3bb10",
"object": "chat.completion",
"created": 1741089755,
"model": "deepseek-r1",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"reasoning_content": null,
"content": "好,用户问“我是谁”,这是一个常见的自我介绍。我不知道用户是谁,可能是学生、刚加入某个组织的人,或者只是单纯想知道是否能自我介绍一次。我需要简洁明了地回答,然后给出进一步的信息,让自己易于理解和喜欢。首先,自我介绍一般包括性别、年龄、兴趣爱好、荣誉和成就等。比如,用户是男性,18岁,喜欢阅读,曾获得Math竞赛冠军,主修统计学,还有学生组织成员。这样可以全面展示一个人的多方面情况。此外,建议用户提供更多信息可以更准确地回答。最后,保持语气友好,采用这样的回复应该能够满足用户的需求。\n</think>\n\n您好!您是想找找自我介绍吗?自我介绍通常包括您自己的性别、年龄、职业、学历等信息。以下是一个简单的自我介绍示例:\n\n**自我介绍**\n您好!我是XXX,是一个18岁的男性,而在2007年被评为某著名跑到�次的著名选手。曾主修统计学,并在Marshallworld上注册为御 hamburger。我希望这段自我介绍能帮助到您,感谢您访问我。\n\n如果您有更多关于您自己或您的问题,随时告诉我哦!(如果您还有其他问题,欢迎提出)。",
"tool_calls": []
},
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null
}
],
"usage": {
"prompt_tokens": 7,
"total_tokens": 265,
"completion_tokens": 258,
"prompt_tokens_details": null
},
"prompt_logprobs": null
}
|
6. 开发一个简单的文本翻译接口
假设我们要使用大模型,提供一个文本翻译的接口。
需求:把输入的中文,翻译成英文。
我们需要使用 python 开发一个 http 服务,提供翻译接口。
首先安装相关 sdk。
1
2
| # 安装openai,fastapi,uvicorn依赖
pip install openai fastapi uvicorn[standard]
|
因为我不需要 deepseek 的思考过程 (<think> 前面的相关内容”), 可以重新部署 deepseek ,添加参数 reasoning-parser 来关闭响应中的思考文本:
1
2
3
4
5
6
7
8
9
10
11
12
13
| python -m vllm.entrypoints.openai.api_server \
--served-model-name deepseek-r1 \
--model /root/model/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B \
--trust-remote-code \
--host 0.0.0.0 \
--port 8080 \
--max-model-len 2048 \
--tensor-parallel-size 1 \
--gpu_memory_utilization 0.8 \
--enforce-eager \
--dtype float16 \
--enable-reasoning \
--reasoning-parser deepseek_r1
|
好,下面可以开始进行 python 脚本的开发工作了。
新建一个脚本文件 deepseek-server.py,内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| from openai import OpenAI
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import re
app = FastAPI()
client = OpenAI(
api_key="xxx",
base_url="http://localhost:8080/v1"
)
class TranslationRequest(BaseModel):
text: str
@app.post("/translate")
async def translate(request: TranslationRequest):
try:
response = client.chat.completions.create(
model="deepseek-r1",
messages=[
{"role": "system", "content": "你是一名专业翻译,需将中文准确翻译为英文,保持原意且语法正确"},
{"role": "user", "content": request.text}
],
temperature=0.3
)
response_txt = response.choices[0].message.content[2:]
return {"translation": response_txt}
except Exception as e:
print(e)
raise HTTPException(status_code=500, detail=str(e))
|
使用 uvicorn 启动服务,端口设置为8000:
1
| uvicorn deepseek-server:app --port 8000 --log-level debug
|
使用 postman 测试翻译接口:
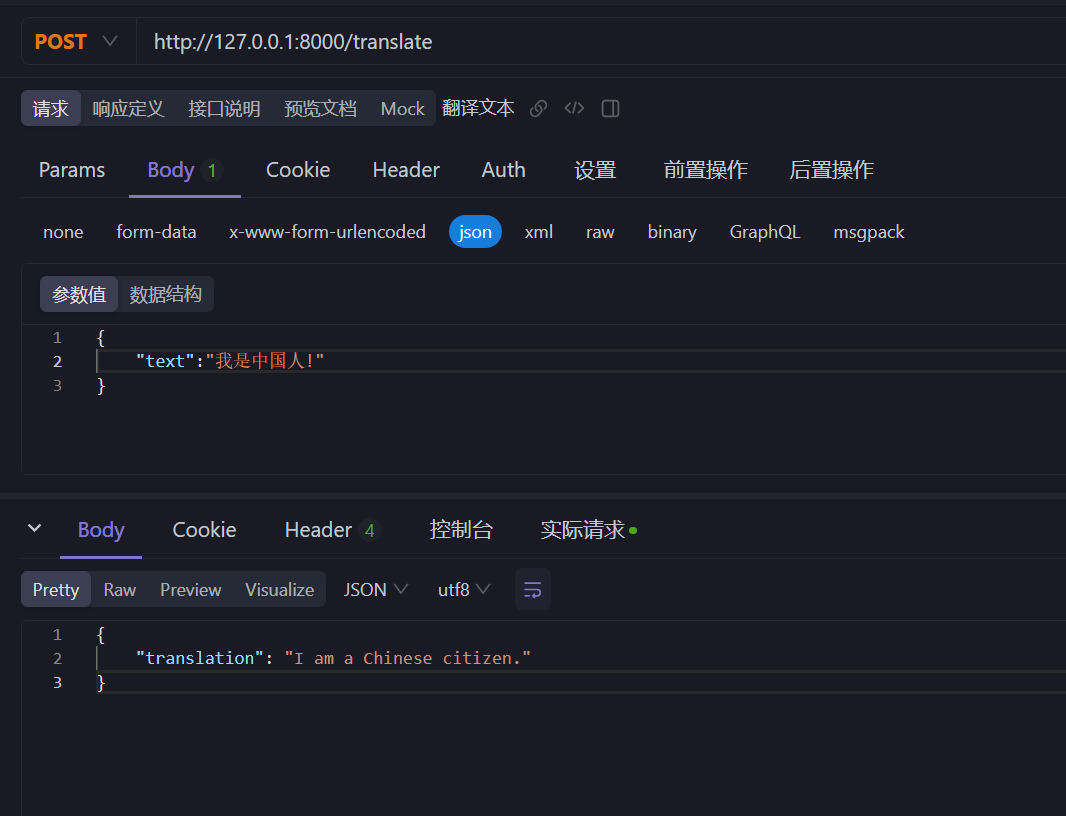
这样一个基于 deepseek 大模型的,简单的翻译接口就开发完成了。
7. 总结
写这篇文章的目的,主要还是让自己能够了解大模型使用的一个基本流程,为后续了解更多的大模型开发知识打个基础。
本人水平有限,如有错误,恳请指正。
8. 参考资料
04-DeepSeek-R1-Distill-Qwen-7B vLLM 部署调用.md.
vLLM CPU和GPU模式署和推理 Qwen2 等大语言模型详细教程
vLLM 部署 DeepSeek-R1
各个系统官方文档和 deepseek 。